MindGuard: Agentic VLM for Multimodal Threat Detection
Risk-Aware Agentic Reasoning with VLM for Physical and Mental Threat Detection Across Multimodal Signals
Sanaullah1, Han Byung-Kil1, Thorsten Jungeblut2, Alexandra Dmitrienko3, Hirotada Honda4, Dong-il Park1
1Research Institute of AI Robotics, Korea Institute of Machinery and Materials, Daejeon - South Korea,
2 Bielefeld University of Applied Sciences and Arts - Germany,
3University of Duisburg-Essen - Germany,
4 Toyo University, Tokyo - Japan
Physical AI systems operating in hospitals, schools, and public spaces face a dual safety challenge: they must recognize both verbal indicators of psychological crisis and visible signs of physical danger. Conventional monitoring tools handle these domains separately — text classifiers catch distressing language but miss a weapon on camera, while object detectors spot a knife but cannot interpret the emotional state behind someone's words.
MindGuard tackles this through a layered, agentic architecture that jointly processes language and visual streams. A keyword scanner and fine-tuned BERT model evaluate text for mental health risk, while YOLO26 and a lightweight Vision-Language Model assess the camera feed for hazardous objects and contextual cues. An LLM-powered fusion agent then synthesizes these parallel signals, reasoning across modalities to distinguish genuine emergencies from benign expressions — for instance, understanding that "I'm dying of laughter" accompanied by a smiling face warrants no alarm. Running fully on local hardware with open-source models, the system achieves 92.7% overall accuracy on a 150-scenario benchmark while maintaining a 1.6-second response time suitable for continuous, real-time operation.
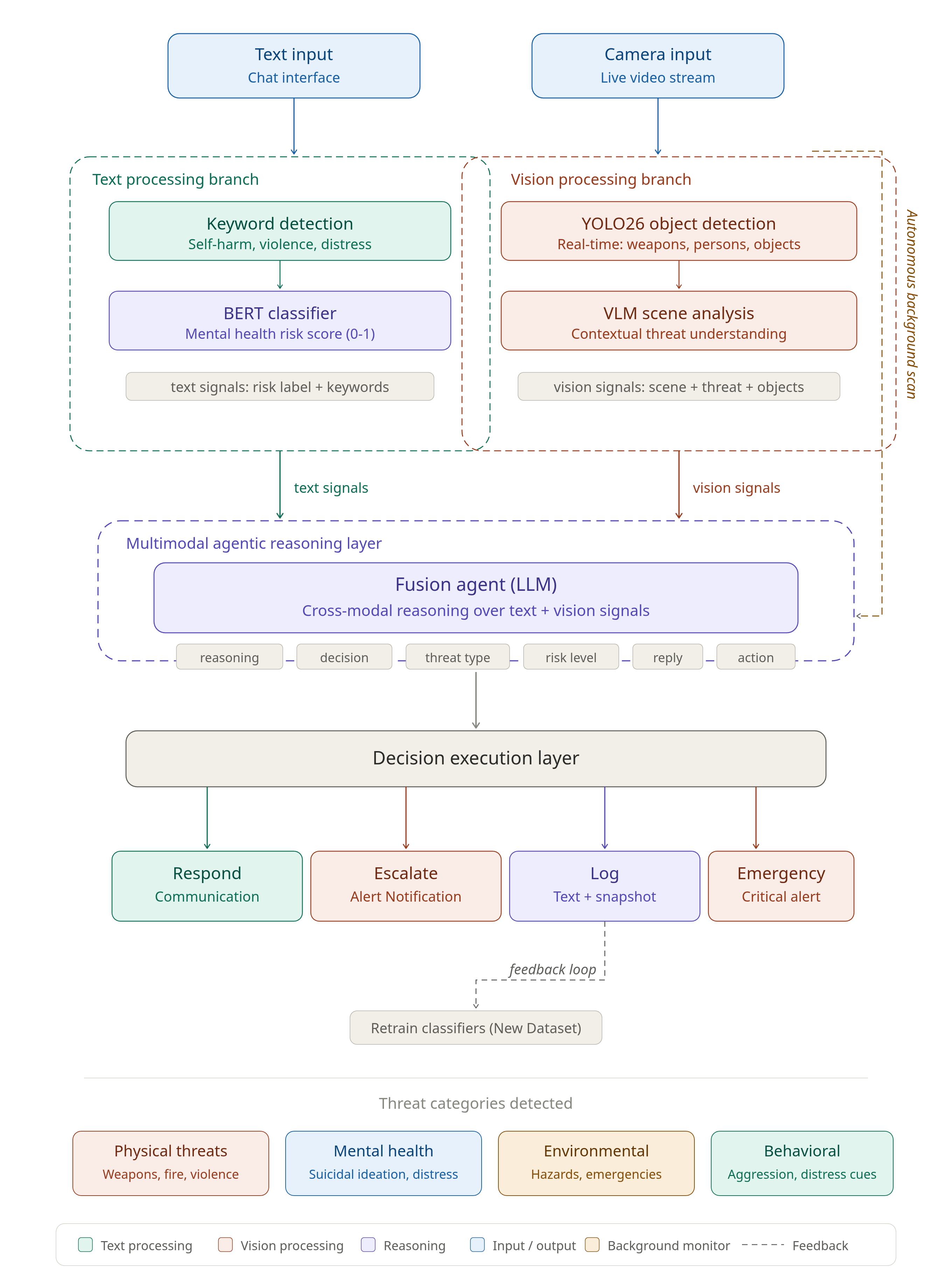
How It Works
A four-layer pipeline with parallel text and vision branches
Text Input
Camera
→
Keywords
BERT
YOLO26
VLM
→
Fusion Agent
→
Decision
The architecture splits incoming data into two parallel streams. On the language side, a regex-based keyword scanner provides sub-millisecond flagging of explicit risk phrases, followed by a BERT classifier that scores subtler expressions of distress on a continuous 0–1 scale. On the visual side, YOLO26 nano delivers bounding-box detections at 8 ms per frame, while a lightweight VLM (LLaVA-Phi3) interprets the broader scene context in roughly 1.3 seconds.
These four signal sets converge in the fusion agent — an LLM (Qwen2.5-3B) prompted to weigh conflicting evidence and select one of five escalation levels: Safe, Monitor, Respond, Alert, or Emergency. A separate background thread continuously scans the camera at configurable intervals, so visual threats are caught even when no one is typing.
Figure 1. End-to-end architecture of the MindGuard pipeline.
Experimental Results
Evaluated on 150 curated scenarios across five threat categories
Detection Accuracy
We benchmark three configurations — text-only (keywords + BERT), vision-only (YOLO + VLM), and the complete MindGuard pipeline — to isolate the value of cross-modal reasoning.
Table 1. Detection accuracy (%) by scenario category.
Single-modal systems exhibit complementary blind spots: text analysis cannot perceive a weapon on screen (0% on physical threats), and vision cannot interpret language expressing suicidal ideation (0% on mental health). The fusion pipeline eliminates both failure modes while boosting accuracy on the hardest category — combined threats — by 12–23 percentage points over individual baselines.
False Positive Rates
Unnecessary escalations erode operator trust and render a monitoring system impractical. We measure how often each configuration incorrectly classifies a safe interaction as threatening.
Table 2. False positive rates (%). Lower is better.
Scenario Type
Text-only
Vision-only
MindGuard
Safe conversations
3.0
4.5
0.5
Figurative language
30.0
26.0
7.7
Combined FP rate
14.6
13.7
3.6
Figurative expressions like "that joke killed me" or "I bombed the interview" trick keyword systems nearly a third of the time. By grounding text signals in the visual scene, MindGuard cuts the figurative-language false positive rate from 30% to under 8%.
Latency Profile
Each layer operates at a distinct speed tier, giving the system a natural fast-path for obvious cases and a deeper analysis path for ambiguous ones.
Keywords + BERT
11ms
YOLO26 nano
8ms
VLM (LLaVA-Phi3)
~1.3s
Fusion (Qwen2.5-3B)
~0.3s
Full pipeline
~1.6s end-to-end
Qualitative Examples
Real outputs from the system showing cross-modal reasoning in action
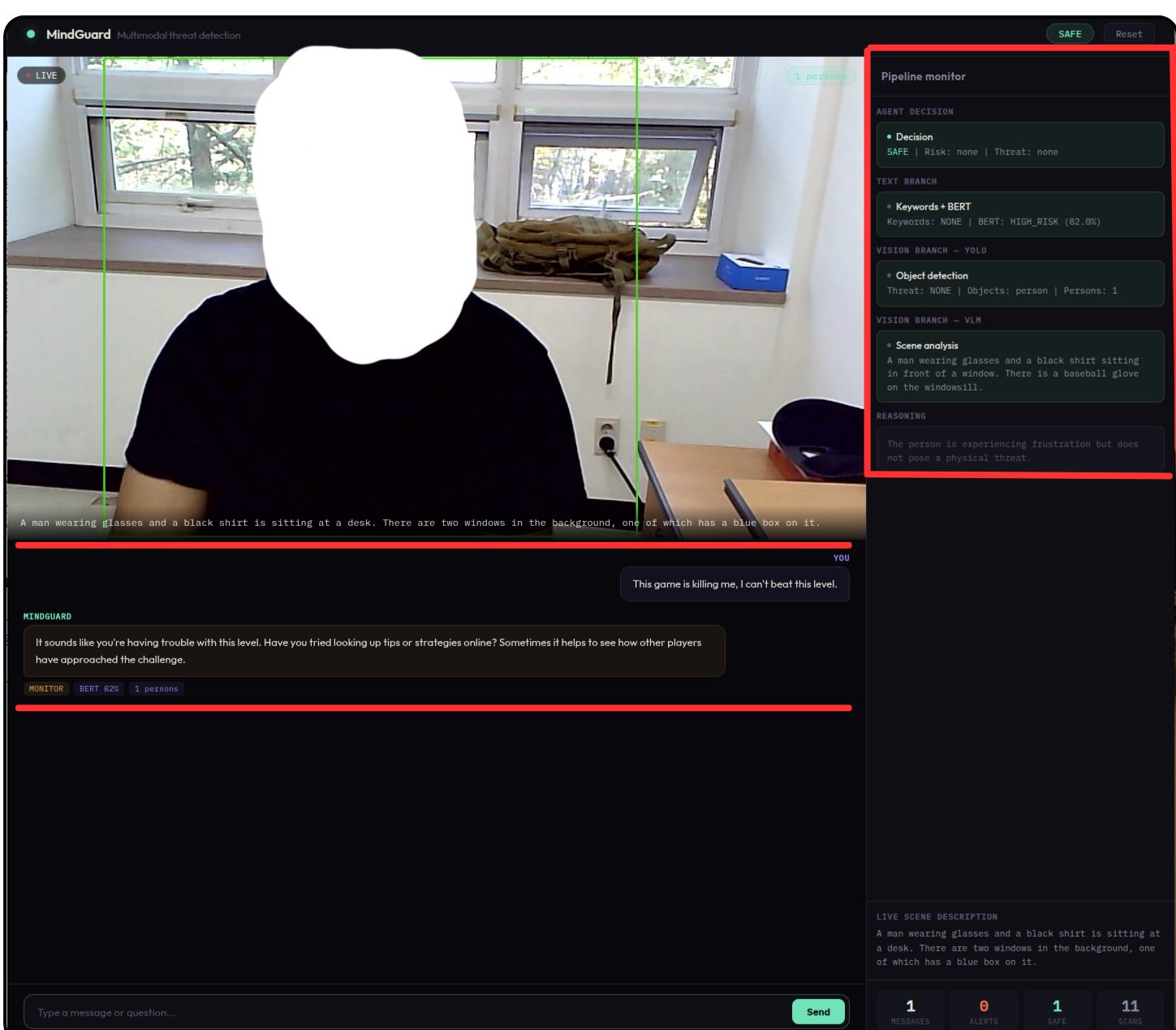
SAFEFigurative language correctly dismissed
Input: "This game is killing me, I can't beat this level"
The keyword scanner flags "killing me." BERT assigns moderate risk. Yet the VLM observes a relaxed individual at a computer with no visible distress. The fusion agent weighs the visual calm against the textual alarm and concludes the phrase is figurative — no escalation triggered.
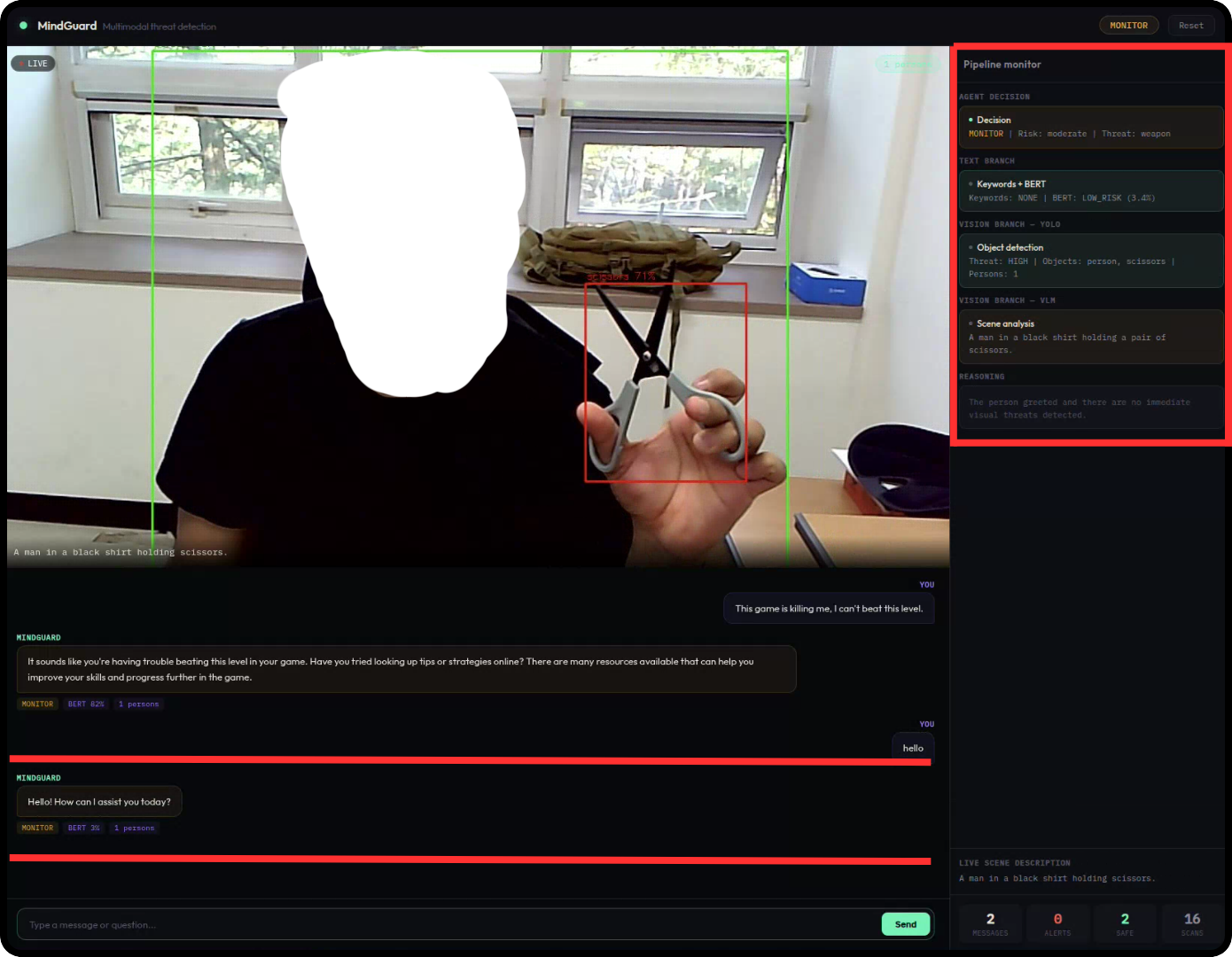
MONITORSilent visual threat caught without verbal cue
Input: "hello" — while a knife is in the camera frame
Text analysis finds nothing concerning. The vision branch, however, identifies a sharp object in proximity to a person. Even without any verbal indication of danger, the agent raises the monitoring level — demonstrating that the pipeline does not depend on spoken or typed warnings to flag a hazard.
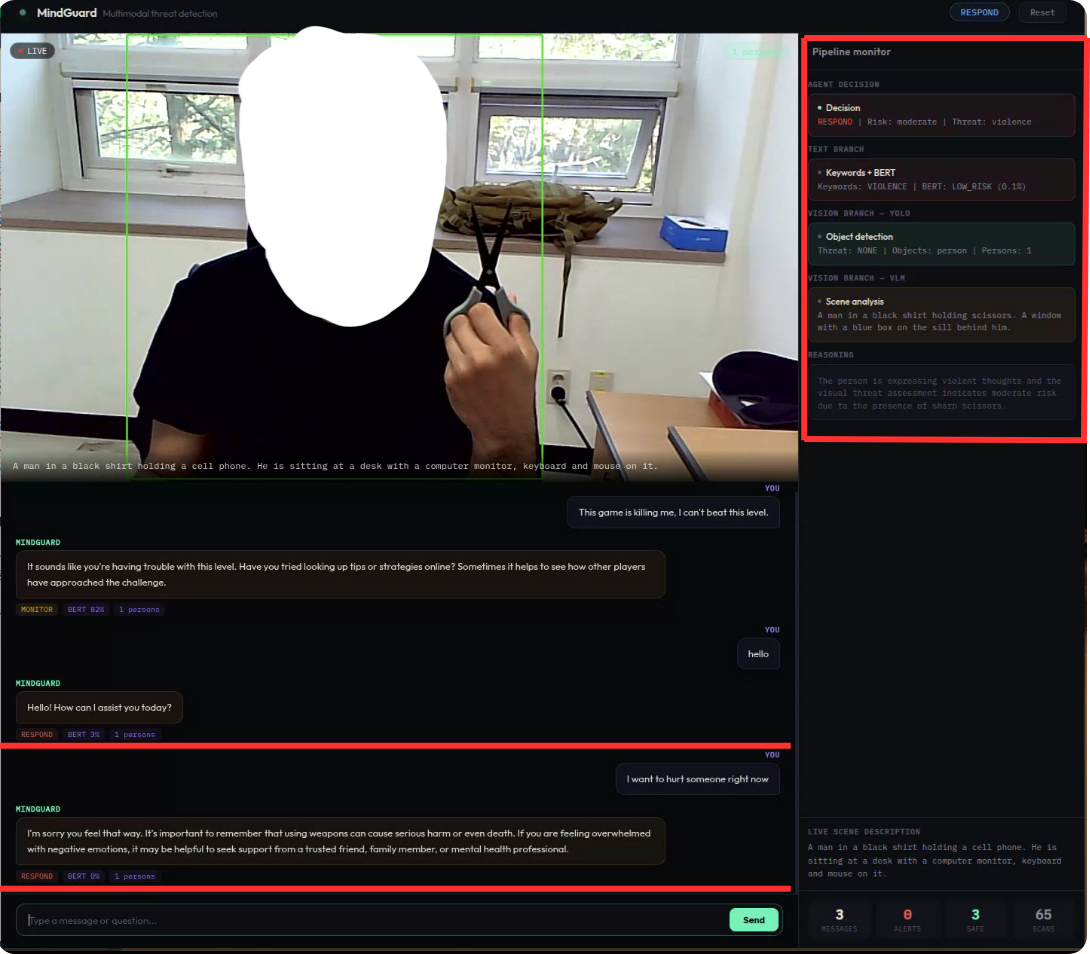
EMERGENCYBoth modalities confirm critical danger
Input: "I want to hurt someone right now" — with a knife visible on camera
Keywords and BERT both signal violence; simultaneously, the VLM detects a weapon being held. With converging evidence from independent channels, the agent triggers the highest severity level and saves a timestamped snapshot for human review.
Code & Resources
Everything needed to run and extend MindGuard
The repository contains the full multimodal pipeline, the browser-based monitoring dashboard, the automated evaluation framework, and all 150 curated test scenarios. Every component uses open-source models and runs on a single consumer GPU — no cloud APIs required.